Critter@home: Content-Rich Traffic Trace Repository from Real-Time,
Anonymous, User Contributions
Members
Overview
Critter@home is a project to connect researchers to
content-rich data from anonymous Internet end-users. Our goal is to
facilitate the safe sharing of data and provide a platform for end-users
to contribute data and be part of the research process.
Problem Statement:
Networking and cybersecurity research critically need publicly available,
fresh and diverse application-level data, for data mining and for
validation.
- There are very few publicly available network traces that contain
application-level data.
- Abailable data is outdated and contains very specific data useful only to some
researchers.
Content-rich network data has enormous privacy risks for sharing, because it
is rich with personal and private information (PPI) that Internet criminals
can monetize E.g., human names, social security numbers, phone numbers, usernames,
passwords, credit card numbers, etc.
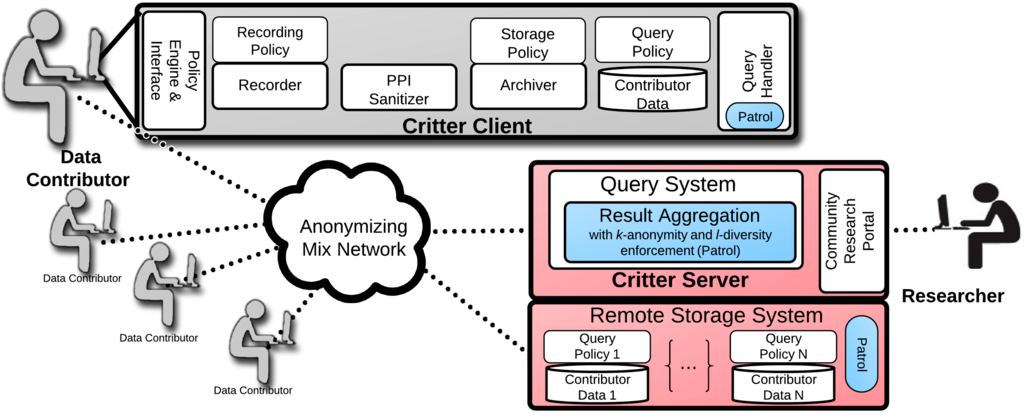
Key Insights
Critter@home is a continuously updated archive of content-rich network data,
contributed by volunteer users. Data contributors join the Critter overlay
whenever online, offering their data to interested researchers.
Privacy of data contributors is protected in multiple ways:
- Contributors have the option of hosting their own data locally, thus
retaining full control over it.
-
Before data is stored, it is modified via a PPI-sanitization process to
replace all personal and private information (PPI).
- Data is always stored and transmitted in an encrypted format.
-
No human apart from the contributor will ever access the raw, PPI-sanitized,
data. Instead, researchers access data via a query system which only returns
aggregate statistics.
- All contact with a contributor is at her discretion and is done via an
anonymizing network where contributor identities are hidden both from
researchers and the Internet at large.
-
Contributors (if they so desire) can have full, fine-grained control over
their data at all times via policy settings.
Our work relies in part on the secure query framework called
Patrol,
developed by PI Mirkovic under another NSF-funded project. This framework
allows only for queries about aggregate features of the data, such as
counts, distributions, etc. and preserves user privacy by applying
k-anonymity and l-diversity principles.
Critter@home Architechture
The Query Process
A query submitted to Critter will go through a five step process illustrated
below.
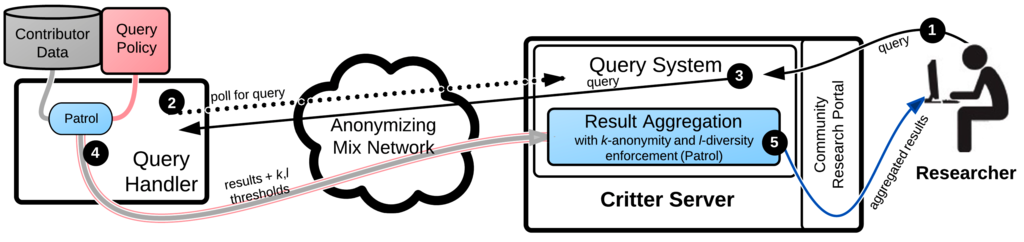
- A researcher submits a query via the public portal.
- Critter clients connect and poll for new queries via an anonymizing
network.
- The researcher's stored query is sent to clients.
- Patrol processes the query if the Query Policy permits, and returns
encrypted results along with information on how a contributor wants its
response aggregated.
- Aggregated results are stored and can be retrieved.
Publications
This material is based upon work supported by the
National Science Foundation under Grant No. 1224035. Any opinions,
findings, and conclusions or recommendations expressed in this material are
those of the authors and do not necessarily reflect the views of the
National Science Foundation.